What the heck is a Support Vector Machine?
Complex data science is not as complex as you think.
This is your explanation to understand Support Vector Machines without prior knowledge!
Let’s go !
What is a Support Vector Machine
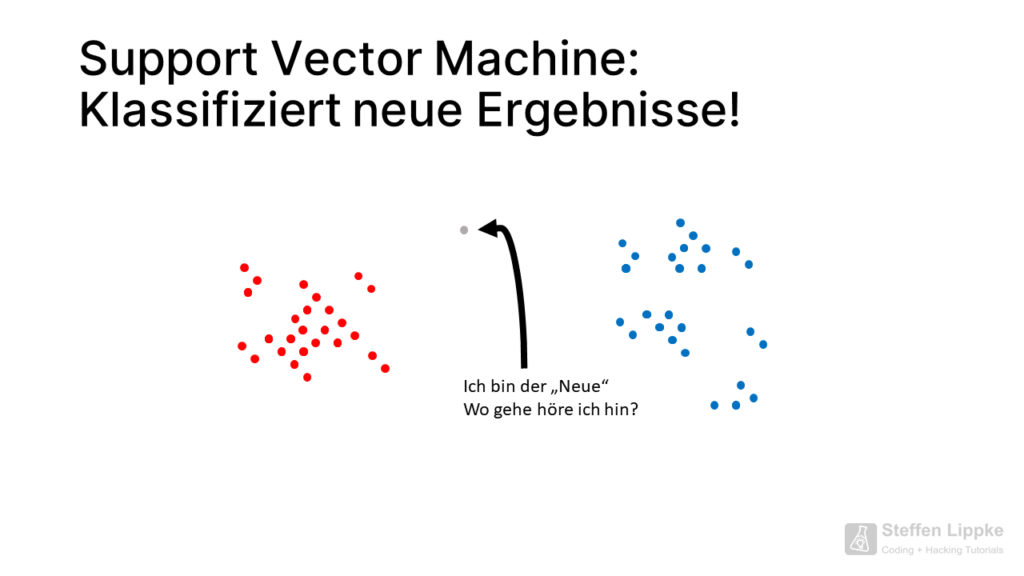
A Support Vector Machine (SVM) is a supervised machine learning model that divides individual objects into classes or sorts new objects into the classes.
Data Scientists, researchers, mathematicians and many others use the SVM for various analysis purposes such as classification. The SVM works with features that a Principal Component Analysis (PCA) has previously determined to be relevant:
Recommended tutorial on this: Principal Component Analysis Explained
Application of the Support Vector Machine
Why do I need an SVM? Data Scientists want to replace expensive, inaccurate and slow human work with efficient mathematical models(Machine Learning). Researchers use SVMs to classify ..
- of easily confused plants
- of similar-looking animals
- of news articles to be assigned to topics
- of ready-to-buy and not-ready-to-buy customers
- of credit repayers and perpetual debtors
The applications of SVMs are unlimited as long as you want to group many objects into two or more classes and you have enough meaningful parameters available.
If you are interested in more Data Science tutorials, you can check out the tutorials in my Data Science category. SVMs are just the beginning.
Explanation with an example
Instead of bombarding you with formulas and weird descriptions, I’ll explain the SVM with a fictional example.
The ancient grizzly vs. the normal grizzly
5300 years ago, an ancient grizzly roamed the forests of Canada. The primeval grizzly weighed 3 tons, was 4 metres high and had 34 cm long teeth (This is all true, of course). Of the skeleton, often only the femur bone remains complete. This looks very similar to the femur bone of today’s grizzly.
The goal and task
When a bone is found, a Support Vector Machine is to recognise whether it is a real original grizzly or a normal grizzly from Canada on the basis of weight and length.
Example: Archaeologist – Bone determination of an ancient grizzly vs. today’s grizzly
Available characteristics from statistics
The Data Scientist need the key characteristics from the researchers to distinguish. The researchers have identified two features that can be used to make a determination in a matter of minutes:
- Weight: continuous interval scale in grams
- Length: continuous interval scale in millimetres

The weight and length of the bone should help distinguish between the ancient grizzly and today’s North American grizzly bears:
| Characteristic bone | Ancestral grizzly | Normal grizzly |
| Weight | 800 – 1200 g | 600 – 900 g |
| Length | 300 – 400 mm | 200 – 300 mm |
When researchers determine the type of grizzly, they have to do a C14 sample to determine the age of the bone. C14 is an isotope of carbon that decays radioactively and is ingested by every living creature with its food. After death, the concentration of C14 decreases year by year, allowing researchers to determine the year of death.
Such a sample is expensive and time-consuming. An SVM can assist researchers by correctly assigning bones based on 95% of the parameters.
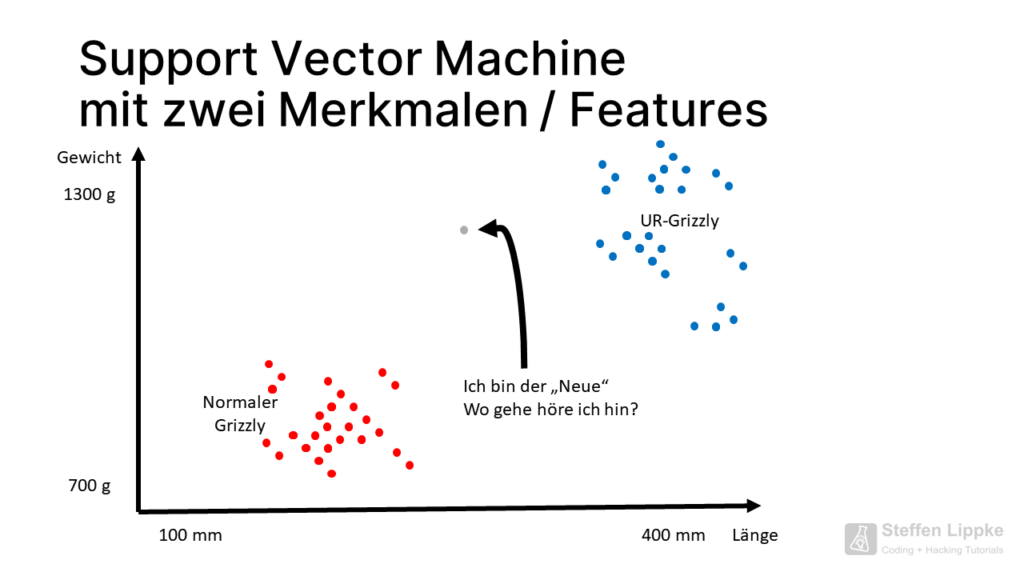
Model with two features
We look at the scatter of the C14 samples performed so far on a graph with two axes.
Weight is plotted on the y-axis and length on the x-axis. The researchers have run 100 C14 samples for 100 bones, which clearly tell us which bear type is present.
The SVM needs a starting data set, a foundation, to work.
A Support Vector Machine places a separation line between the two point clouds f(x) = mx + b,which separates the clusters.
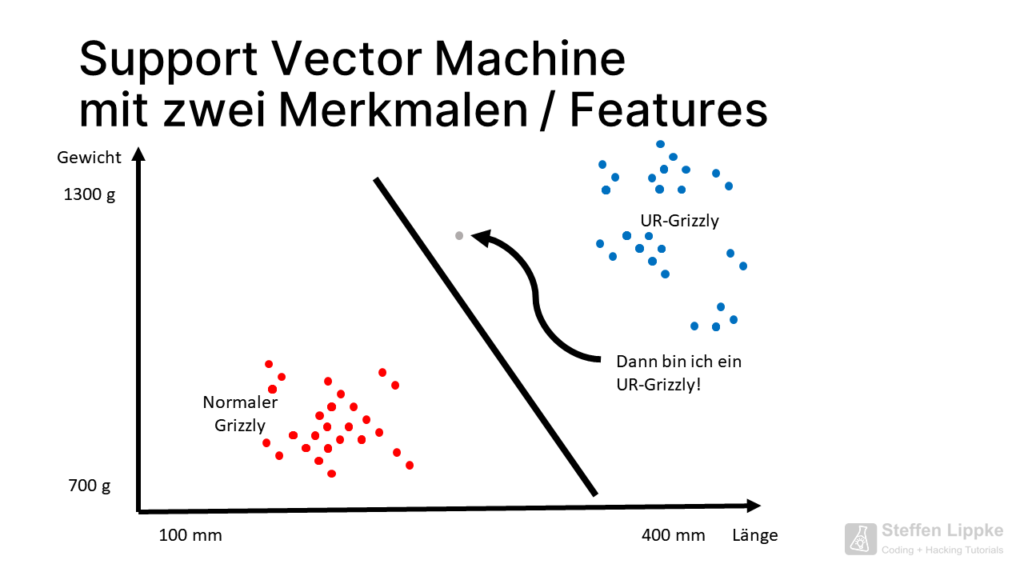
Challenge with Support Vector Machines
Problem: How does the SVM distinguish a baby grizzly that died from a giant grizzly from modern times?
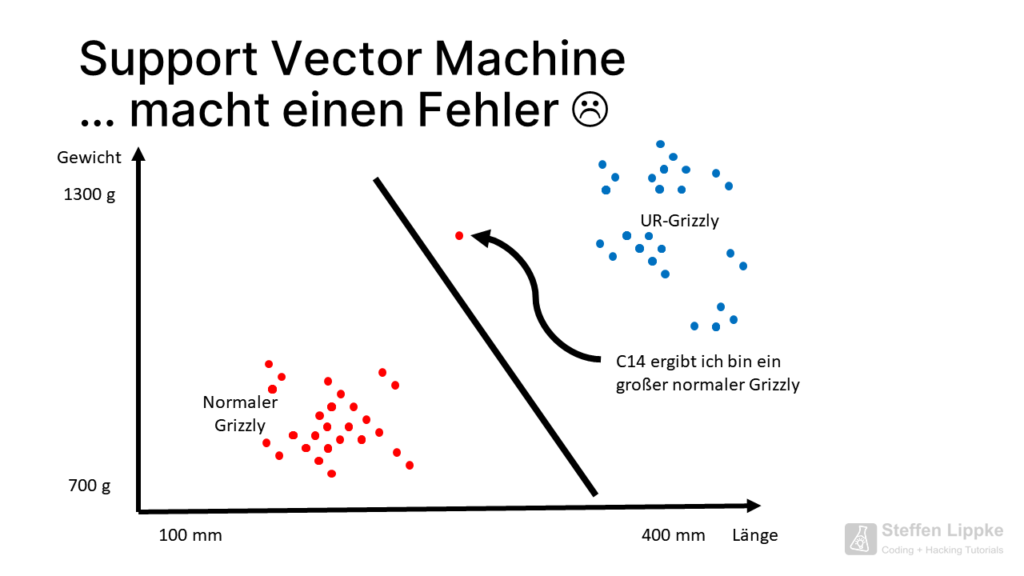
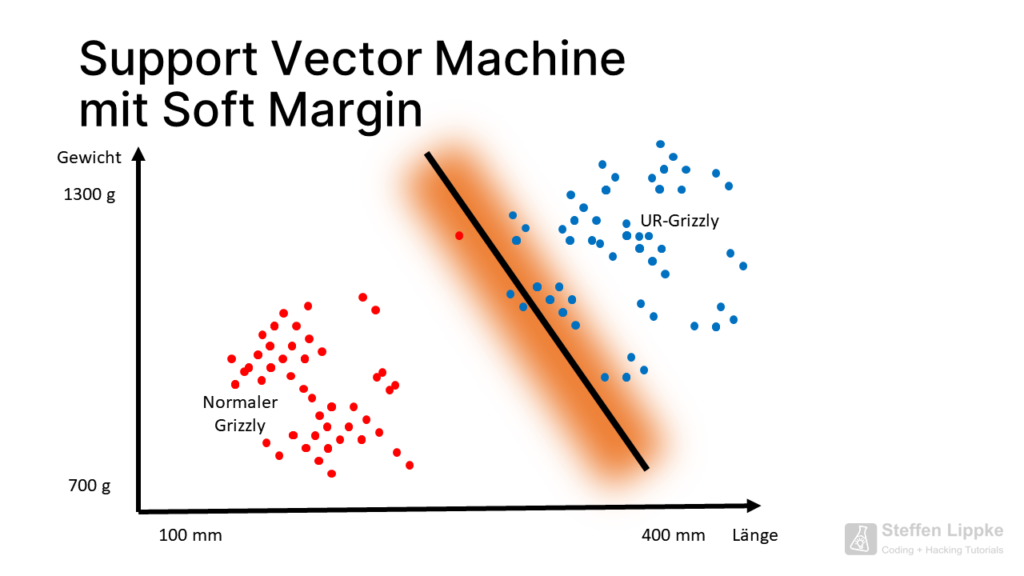
Some points of the primal grizzly are close to the point cloud of the normal grizzly. If a new C14 sample shows that the bone of a present-day giant grizzly is present, the SVM must shift its separation line.
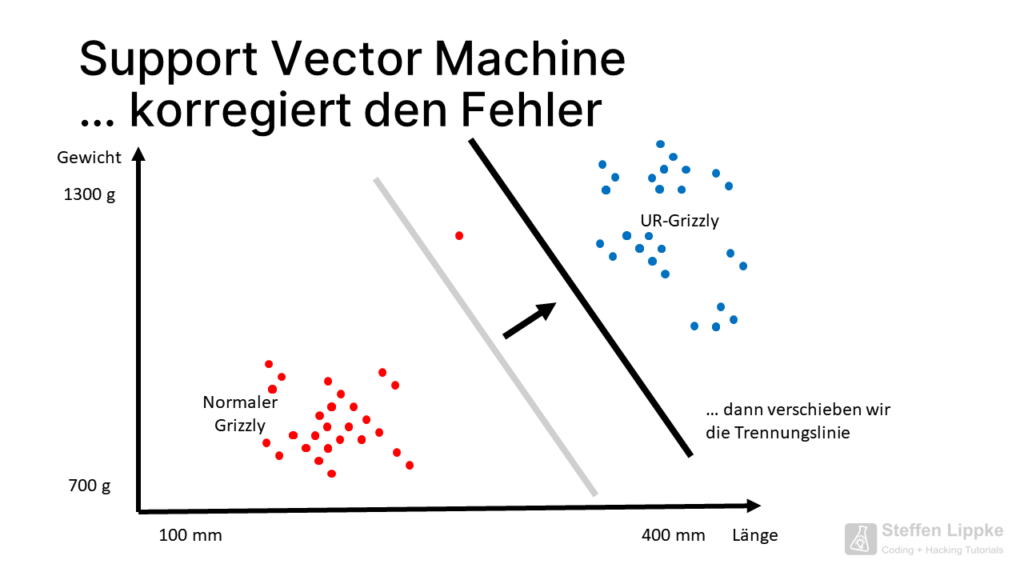
The SVM does not like outliers.
The Miss Classifications
Watch out!
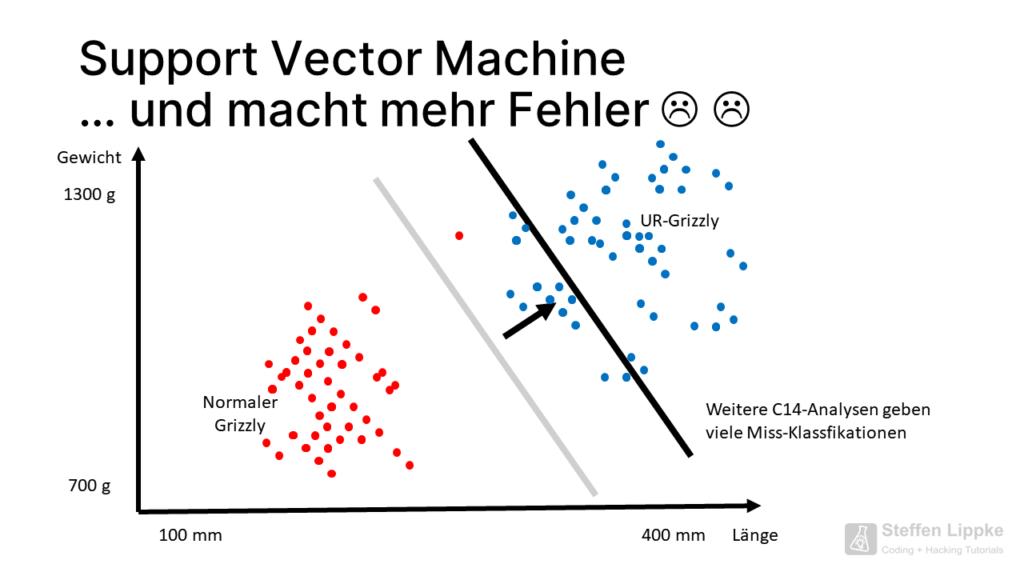
More C14 samples show even more mis-classifications. Why does the SVM have to shift the degrees of separation so far?
If the SVM pulls the straight line back a few centimetres, the number of future mis-classifications drops considerably. In this position, the SVM is correct in most cases.
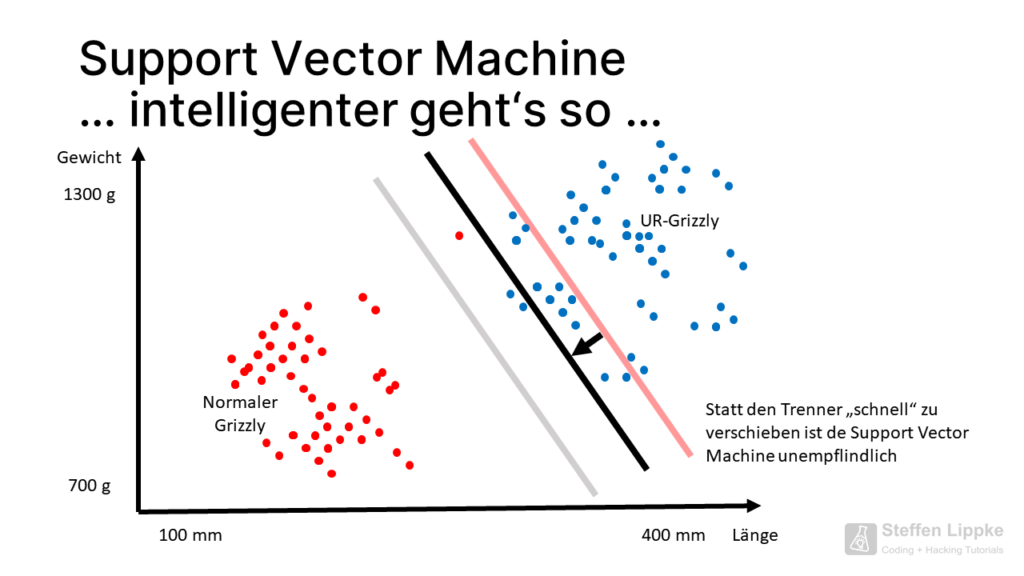
Types of Margins
The SVM uses the following margins:
- The Data Scientist used the “soft margin” when they are not directly separable with a line
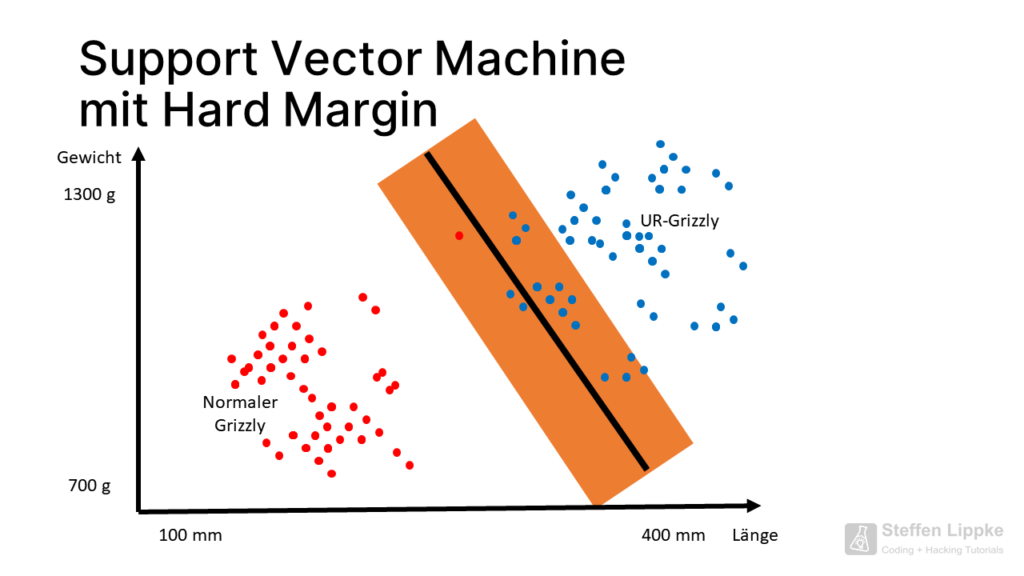
- Hard Margin are separable with a line or a hyperplane (plane in the 3D coordinate system)
Practical implementation with Python
You can use Python and the machine learning library scikit-learn to implement many projects in the field of data science. These include, for example :
- Classification
- Regression
- Clustering
- Reduction of dimensions
- Model selection
The function shuffel randomly distributes the classified features into a test dataset and a training dataset.
from sklearn.utils import shuffle
X, Y = shuffle(X,Y)
The function Cross_validation creates the actual support vector machine.
from sklearn.cross_validation import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, Y, train_size=0.9)
If you want to start your first steps with Machine Learning, then start your journey with the ‘Programming AI yourself’ tutorial.
#Import des Bib
from sklearn import svm
# Klassifzierung mit dem Support Vector und Linaren Kernel
model = svm.SVC(kernel='linear')
# Beginne das Traing
model.fit(X_train, y_train)
# Klassifziere die neuen Beispiele und überprüfe diese
y_pred = model.predict(X_test)What is the kernel trick?
SVMs don’t just support linear dividers.
When there are multiple dimensions, the SVM creates a plane that separates the clusters. Alternatively, the SVM uses radial or polynomial kernels that extend separation by linear/planar planes through curved separators. An SVM cannot separate the clusters in all cases.
The SVM is only as good as the basic model. You, as a human, have to sort many data points correctly. The SVM will reproduce any error you give the model to calculate during initial loading. Look for high quality data that is available in a high quantity.
Support Vector Machine with 3+ features
An SVM can handle multiple variables.
Use multiple features (dimensions) to model other features such as width, bone density, fracture strength, etc. in the SVM.
With three features, the SVM separates the clusters in a 3D coordinate system using a plane.
A graphical representation of 5 dimensions or more is only confusing. Mathematically, models with 3+ dimensions are feasible. The more features an SVM has, the more computing power your computer needs.


