
Was zum Henker ist eine Support Vector Machine?
Komplexes Data Science ist gar nicht so komplex wie Du glaubst.
Das ist Deine Erklärung, um die Support Vector Machines ohne Vorwissen zu verstehen!
Auf geht’s !
Was ist eine Support Vector Machine
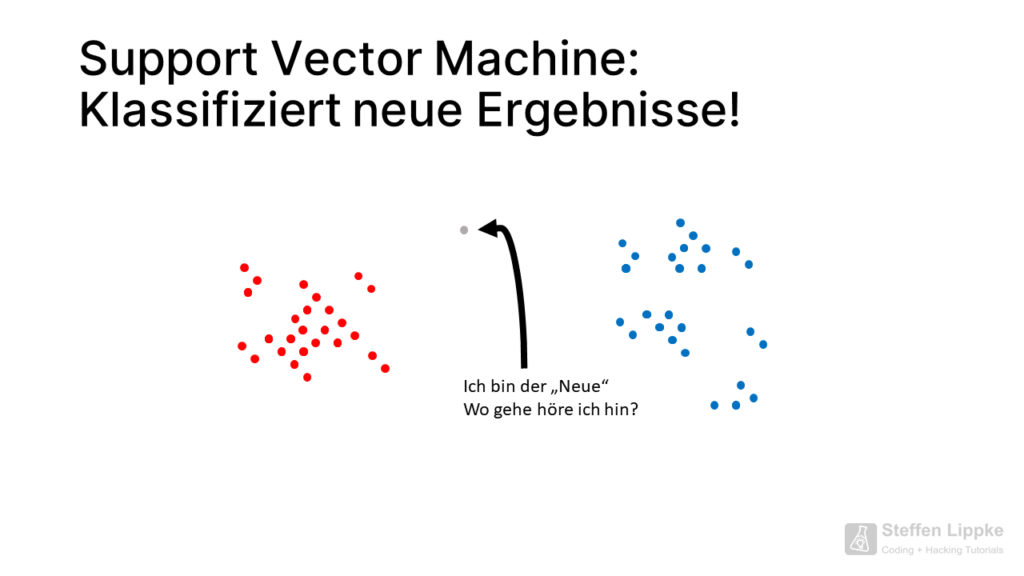
Eine Support Vector Machine (SVM) ist ein überwachtes Machine Learning Modell, welches einzelne Objekte in Klassen aufteilt oder neue Objekte in die Klassen einsortiert.
Data Scientists, Forscher, Mathematiker und viele andere nutzen die SVM für verschiedene Analyse-Zwecke wie die Klassifikation. Die SVM arbeitet mit Features, die eine Principal Component Analysis (PCA) vorher als relevant festgelegt hat:
Empfehlenswertes Tutorial dazu: Principal Component Analysis erklärt
Anwendung der Support Vector Machine
Warum brauche ich eine SVM? Data Scientists wollen die teure, ungenaue und langsame menschliche Arbeit durch effiziente mathematische Modelle (Machine Learning) ersetzen. Forscher nutzen SVMs zur Klassifikation …
- von einfach verwechselbaren Pflanzen
- von ähnlich aussehenden Tieren
- von Nachrichten-Beiträgen, die den Themen zugeordnet werden sollen
- von kaufbereiten und nicht-kaufbereiten Kunden
- von Kredit-Rückzahlern und Ewige-Schulder
Die Anwendungen von SVMs sind unbegrenzt, solange Du viele Objekte in zwei oder mehrere Klassen gruppieren möchtest und Du genügend aussagekräftige Parameter zur Verfügung hast.
Wenn Du Dich für weitere Data Science Tutorials interessierst, kannst Du Dir mal die Tutorials in meiner Kategorie Data Science ansehen. SVMs sind erst der Anfang.
Erklärung mit einem Beispiel
Anstatt Dich mit Formeln und komischen Beschreibungen zu bombardieren, erkläre ich Dir die SVM anhand eines fiktiven Beispiels.
Der Ur-Grizzly vs. normaler Grizzly
Vor 5300 Jahren machte ein Ur-Grizzly die Wälder von Kanada unsicher. Der Ur-Grizzly war 3 Tonnen schwer, 4 Meter hoch und hatte 34 cm lange Zähne (Das ist natürlich alles wahr). Von dem Skelett bleibt oft nur der Oberschenkel-Knochen vollständig erhalten. Dieser sieht dem Oberschenkel-Knochen des heutigen Grizzlys sehr ähnlich.
Das Ziel und Aufgabenstellung
Eine Support Vector Machine soll bei dem Fund eines Knochens anhand von Gewicht und Länge erkennen, ob es sich um einen echten Ur-Grizzly handelt oder einen normalen Grizzly aus Kanada.
Beispiel: Archäologe – Knochenbestimmung von einem Ur-Grizzly vs. heutiger Grizzly
Verfügbare Merkmale aus der Statistik
Die Data Scientist brauchen die wesentlichen Merkmale von den Forschern zur Unterscheidung. Die Forscher haben zwei Merkmale erkannt, mit der eine Bestimmung in wenigen Minuten möglich ist:
- Gewicht: kontinuierliche Intervallskala in Gramm
- Länge: kontinuierliche Intervallskala in Millimeter

Das Gewicht und die Länge des Knochens soll bei der Unterscheidung zwischen dem Ur-Grizzly und den heutigen nordamerikanischen Grizzlybären helfen:
| Merkmal Knochen | Ur-Grizzly | Normaler Grizzly |
| Gewicht | 800 – 1200 g | 600 – 900 g |
| Länge | 300 – 400 mm | 200 – 300 mm |
Wenn die Forscher den Grizzly-Typen bestimmen, müssen diese eine C14-Probe durchführen, um das Alter des Knochens zu bestimmen. C14 ist ein Isotop des Kohlenstoffs, der radioaktiv zerfällt und jedes Lebewesen mit der Nahrung aufnimmt. Nach dem Tod sinkt Jahr für Jahr die Konzentration von C14 ab, sodass die Forscher das Todesjahr bestimmen können.
Eine solche Probe ist teuer und zeitaufwendig. Eine SVM kann die Forscher unterstützen, indem sie auf Basis der Parameter zu 95 % korrekt die Knochen zu ordnen kann.
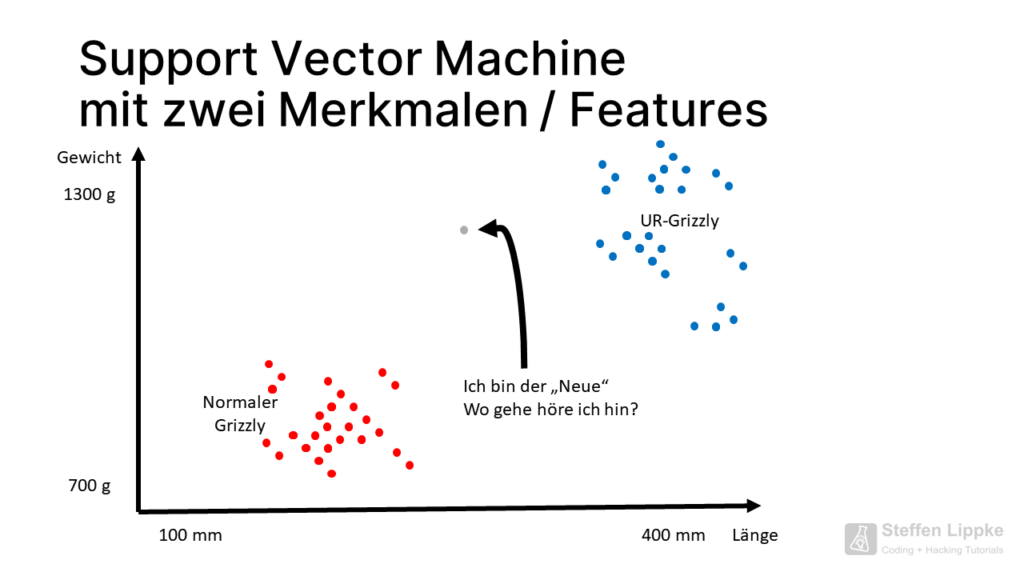
Modell mit zwei Merkmalen
Wir sehen uns die Streuung der bisherigen durchgeführten C14-Proben auf einem Diagramm mit zwei Achsen an.
Das Gewicht ist auf der y- und die Länge auf der x-Achse abgebildet. Die Forscher haben 100 C14-Proben für 100 Knochen durchgeführt, die uns eindeutig sagen, welcher Bären-Typ vorliegt.
Die SVM braucht ein Startdatenset, eine Grundlage, um zu funktionieren.
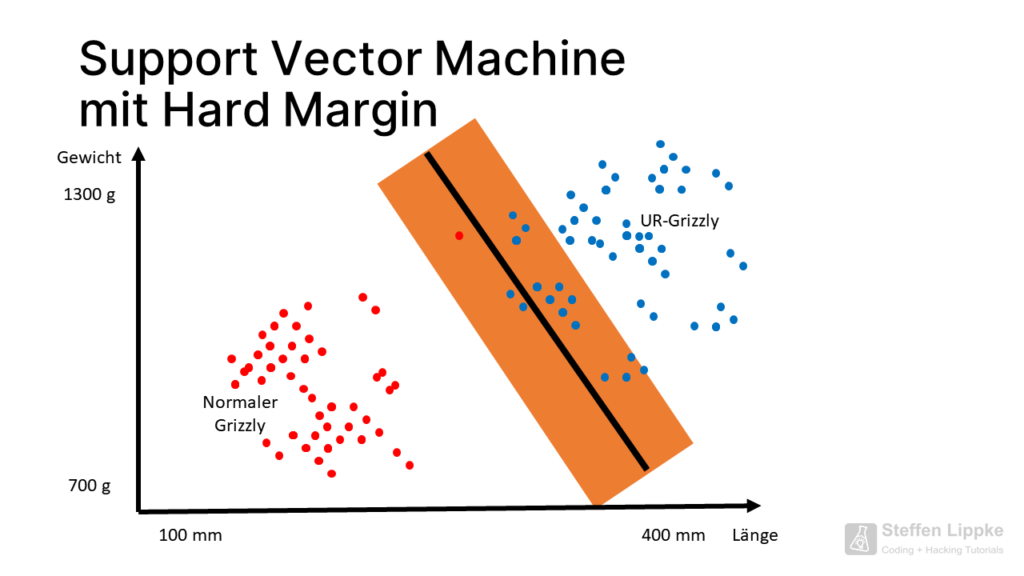
Eine Support Vector Machine legt eine Trennungsgerade zwischen die zwei Punktewolken f(x) = mx + b,welche die Cluster voneinander abtrennt.
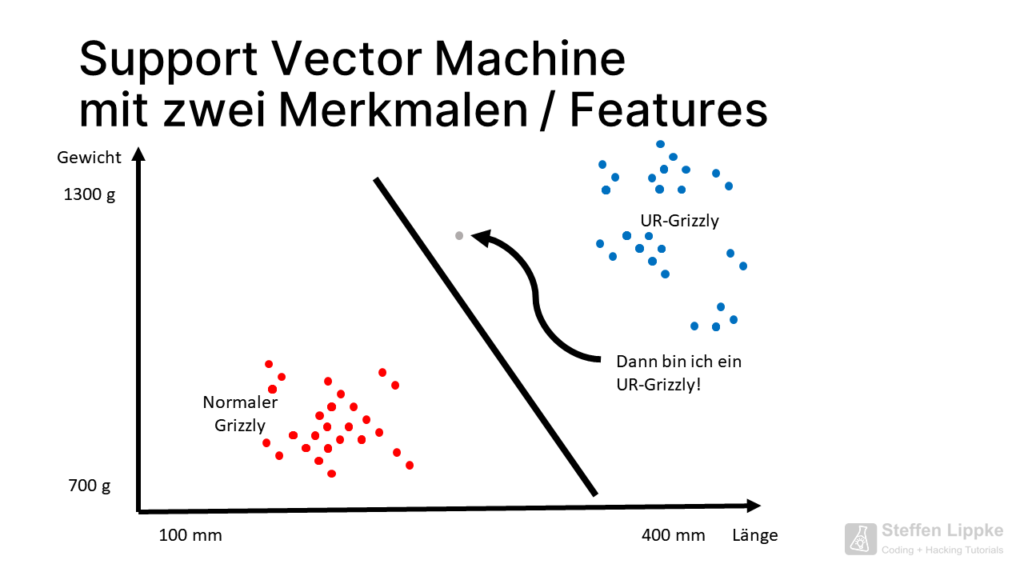
Herausforderung mit Support Vector Machines
Problem: Wie unterscheidet die SVM einen gestorbenen Baby-Ur-Grizzly von einem Riesen-Grizzly aus der heutigen Zeit?
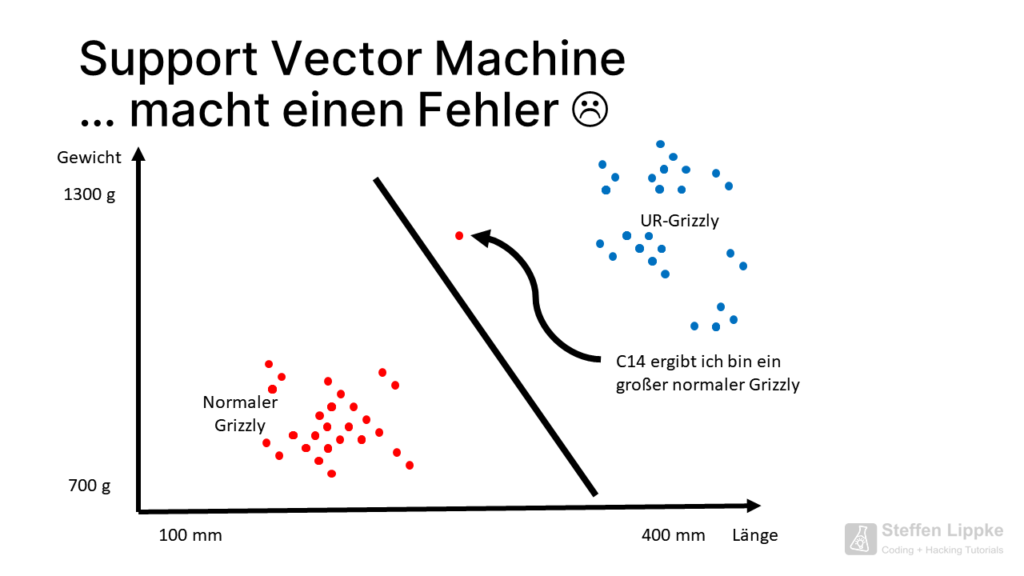
Einige Punkte des Ur-Grizzlys liegen dicht an der Punktewolke des normalen Grizzlys. Wenn eine neue C14-Probe ergibt, dass der Knochen eines heutigen Riesen-Grizzlys vorliegt, muss die SVM ihre die Trennungsgerade verschieben.
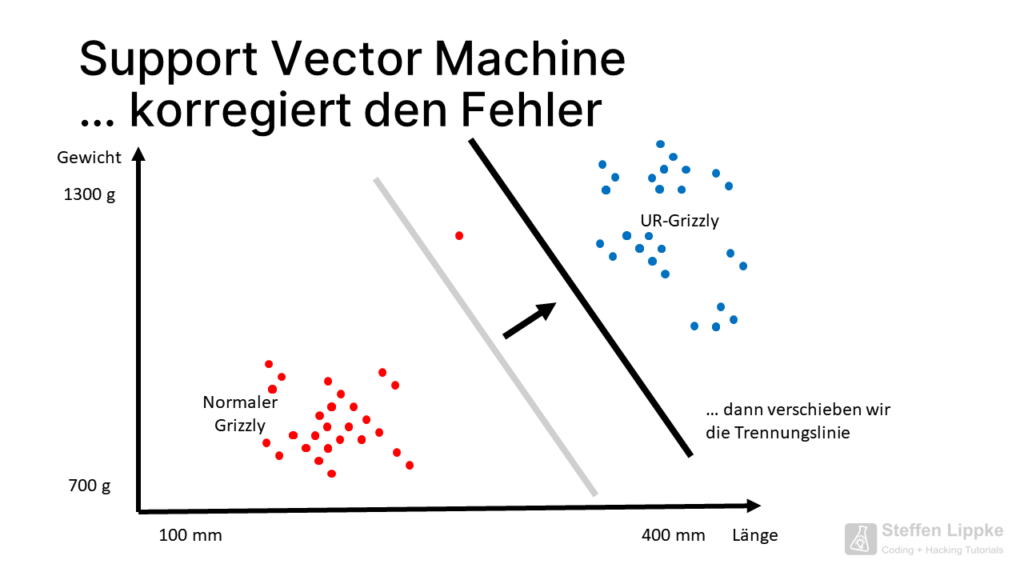
Die SVM mag keine Ausreißer.
Die Miss-Klassifikationen
Vorsicht!
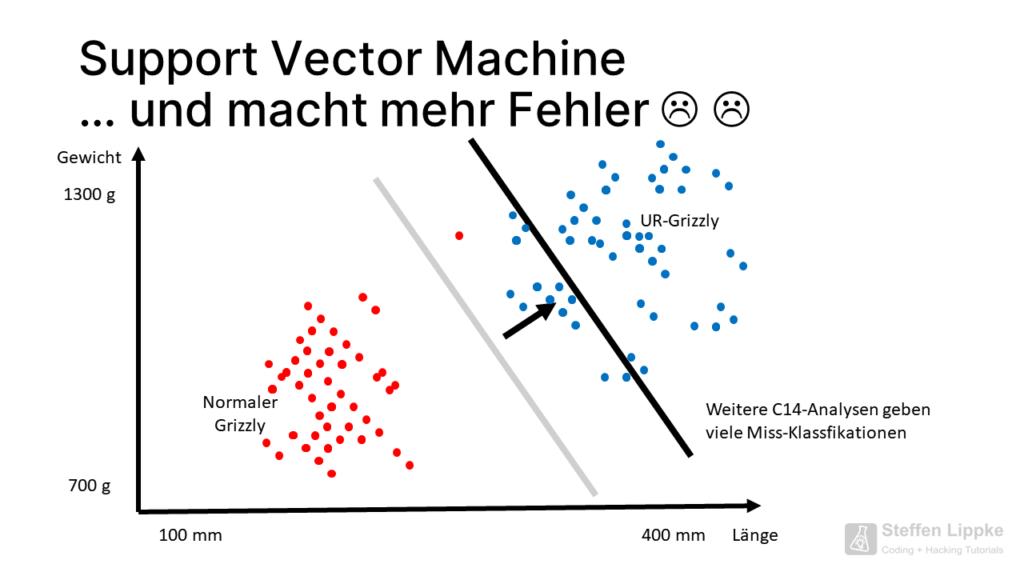
Weitere C14-Proben zeigen noch mehr Miss-Klassifikationen auf. Warum muss die SVM die Trennungsgrade so weit verschieben?
Zieht die SVM die Gerade ein paar Zentimeter zurück, sinkt die Anzahl der zukünftigen Miss-Klassifikationen erheblich. In dieser Position liegt die SVM in den meisten Fällen korrekt.
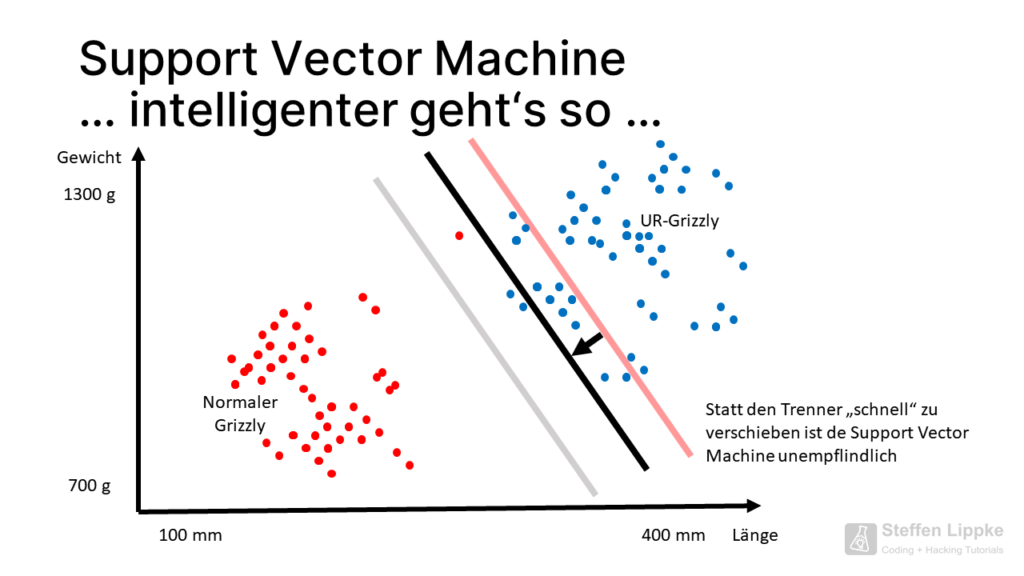
Arten von Margins
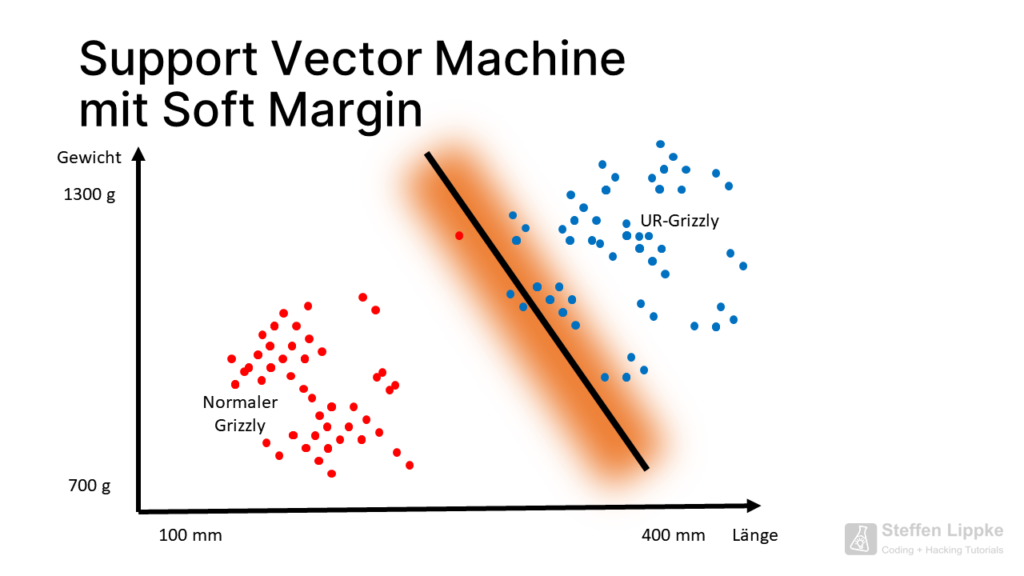
Die SVM nutzt folgende Abstände:
- Die Data Scientist nutzten den „weicher Abstand“ (Soft Margin), wenn diese nicht direkt mit einer Linie trennbar sind
Praktische Umsetzung mit Python
Du kannst mit Python und der Machine-Learning-Bibliothek scikit-learn viele Projekte im Bereich der Data Science umsetzen. Dazu gehören z. B. :
- Klassifikation
- Regression
- Clustering
- Reduktionen der Dimensionen
- Modellauswahl
Die Funktion shuffel verteilt zufällig die klassifizierten Merkmale in einen Testdatensatz und ein Trainingsdatensatz.
from sklearn.utils import shuffle
X, Y = shuffle(X,Y)
Die Funktion Cross_validation erstellt die eigentliche Support Vector Machine.
from sklearn.cross_validation import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, Y, train_size=0.9)
Wenn Du erste Schritte mit Machine Learning starten willst, dann beginne mit dem ‚KI selbst Programmieren‘ Tutorial Deine Reise.
#Import des Bib
from sklearn import svm
# Klassifzierung mit dem Support Vector und Linaren Kernel
model = svm.SVC(kernel='linear')
# Beginne das Traing
model.fit(X_train, y_train)
# Klassifziere die neuen Beispiele und überprüfe diese
y_pred = model.predict(X_test)Was ist der Kernel-Trick?
Die SVMs unterstützen nicht nur die linearen Trennungslinien.
Bei mehreren Dimensionen erstellt die SVM eine Ebene, die die Cluster voneinander trennt. Alternativ verwendet die SVM radiale oder polynomiale Kernel, die Trennung durch lineare / planer Ebenen durch geschwungene Trenner erweitert. Eine SVM kann nicht in allen Fällen die Cluster voneinander trennen.
Die SVM ist nur so gut, wie das Grundlagenmodell. Du musst als Mensch viele Datenpunkte richtig einsortieren. Die SVM reproduziert jeden Fehler, den Du bei der Initialladung dem Modell zum Rechnen gibst. Achte auf hochqualitative Daten, die in einer hohen Quantität verfügbar sind.
Support Vector Machine mit 3+ Merkmalen
Eine SVM kommt mit mehreren Variablen zurecht.
Nutze mehrere Features (Dimensionen), um andere Merkmale wie die Breite, Knochendichte, Bruchfestigkeit usw. in der SVM zu modellieren.
Bei drei Merkmalen trennt die SVM die Cluster in einem 3D-Koordinatensystem anhand einer Ebene.
Eine grafische Darstellung ab 5 Dimensionen ist nur verwirrend. Mathematisch sind Modelle mit 3+ Dimensionen umsetzbar. Je mehr Features eine SVM hat, desto mehr Rechenpower braucht Dein Computer.


