
Du möchtest eine künstliche Intelligenz programmieren?
Ich zeige Dir die wesentlichen Grundlagen und 3 Methoden, wie Du Deine erste KI programmieren kannst.
Beginnen wir!
Was ist eine Künstliche Intelligenz?
Weil die Informatiker sich bis heute auf keine endgültige und einheitliche Definition geeinigt haben, kannst Du fast jede Software „als künstlicher Intelligenz“ verkaufen. Ich (und andere Informatiker) verbinden mit einer künstlichen Intelligenz Begriffe wie neuronale Netze, Tensors, Split-Training, LLMS, Gewichtung und große Datensätze.
Du könntest ein Programm bereits als KI bezeichnen, wenn diese mit einer If-Anweisung auf einen Schwellwert prüft.
Wenn Person die Person 1,90 m groß ist und 108,3 kg schwer ist, dann ist diese übergewichtig.
Diese Prinzip nennt sich ein Entscheidungsbaum und das Fraunhofer-Institut nennt diese System bereits KI.
Die künstliche Intelligenz, die ich folgend hier beschreibe, basiert auf Statistik und Stochastik, einen Teil der Mathematik, der sich mit Datenanalyse und Wahrscheinlichkeiten beschäftigt. Die langweiligsten Vorlesungen im Studium sind die spannendsten und relevantesten Fächer für KI, die Du belegen kannst. Du musst aber nicht studieren, um eine KI zu programmieren. Trotzdem solltest Du Dir die Grundlagen anschauen, damit Du die Tutorials im Internet im Hintergrund besser verstehst.
So du willst jetzt aber verstehen, wie eine „echte“ KI funktioniert, welche die News die letzten Jahre dominiert haben. Jetzt gehts los:
Funktion von klassischer Software
Um die Idee hinter einer KI zu verstehen, müssen wir das Konzept zu einem Modell umwandeln.
Klassische Software arbeitet nach dem folgenden Schema:
Software + Daten => Ergebnisse
- Buchungssoftware + unbearbeitete Transaktionslisten => Gebuchte Transaktionen
- Newslettersoftware + Mailingliste => Inforierte Nutzer
- Navigationssysteme + Kartenmaterial => Berechnete Route
Funktion von künstlicher Intelligenz
Eine Künstliche Intelligenz dreht die klassiche Software-Idee auf den Kopf:
Daten + Ergebnisse => Software (KI) und weiter KI + Eingaben (neue Daten) => Ergebnisse
Drehen wir das Ziel um!
- Schulaufsätze + Korrekturen von Lehren => Grammatiksoftware
- Bilder + Betitelung der Bilder durch Menschen => Bildererkennungssoftware
- Scans + von Menschen abgetippte Texte => Texterkennungssoftware (OCR)
Die entstandene Software (Model) kann neuartige, unbekannte Anwendungsfälle bearbeiten. Ein Programmierer muss nicht die Logik einprogrammieren, sondern der Computer bringt sich die Fähigkeit bei. Der Computer erlernt nicht die Fähigkeit an sich, sondern versucht Muster zu erkennen und diese bei neuen Angaben vorzusetzen.
- Die Grammatiksoftware erkennt Fehler in Sätzen, welche sie nie vorher verarbeitet hat.
- Die Bilderkennungssoftware betitelt unbekannte neue Bilder.
- Die Texterkennungssoftware kann den Text aus unbekannten Scans extrahieren.
Wenn Du mehr über den Unterschied zwischen künstlicher Intelligenz, Machine Learning und Deep Learning erfahren willst, dann vertiefe Dich in die folgenden Beiträge:
Grundlagen für die Künstliche Intelligenz
Die Schule und Uni vermitteln Theorie Kram, den Du nie wieder brauchst.
Spaß macht die Theorie, wenn Du einen konkreten Anwendungsfall, eine Herausforderung auf den Tisch liegen hast.
Wenn Du Dir das Ziel setzt eine künstliche Intelligenz zu programmieren, dann hast Du direkt die notwendige Motivation in die theoretischen Grundlagen einzutauchen.
Für Deine KI brauchst Du …
- Statistik
- Stochastik
- Programmiersprache
- Einen Computer
Ein Data Scientist nennen die Arbeitgeber die Statistiker von früher. Mit der Umbenennung sind langweilige trockene Fächer auf einmal hipp.
Methoden und Modelle
Eine künstliche Intelligenz kannst Du mit vielen mathematischen Modellen programmieren (sehr einfach bis hoch-komplex). Du musst austesten, welches Model für Deinen Anwendungsfall am besten funktioniert.
Die beliebtesten „hippen“ Methoden sind …
- Rekursive Neuronale Netze (Alexa)
- Große Sprachmodelle (ChatGPT)
- Tensor (FaceID)
Diese (teils komplexen) Vorgehensweisen produzieren bei vielen Anwendungsfällen keine besseren Ergebnisse als die „klassischen“ Methoden …
- Regression
- Clustering
- Extremwert Erkennung
Je nach Anwendungsfall muss der Data Scientist mit allen Methoden experimentieren und sich nicht nur auf die hippen Methoden beschränken. Ein Data Scientist programmiert keine KI, sondern spielt solang mit den Parametern herum, bis dieser die richtigen Einstellungen gefunden hat. Die optimalen Wert findest Du nicht mit Theorie, sondern mit Try-and-Error.
Ergebnisse und Daten zum Trainieren
Alle KI-Methoden brauchen Daten. Die Datengrundlage soll …
- Quantität: KI-Systeme erstellen mit mehr Trainingsdaten bessere Modelle. Je besser das Modell ist, desto besser sind die Ergebnisse.
- Qualität: Fehlerfrei beschriftete Datenpunkte sind essenziell, weil die KI etwas Falsches lernt. Die Trainingsdaten sollten möglichst Störfaktor-frei, valide und gefiltert sein.
Link Tipps:
- Kaggle Datasets
- Google Dataset Search
- Projekte zu Bevölkerung: Boston Housing
3 Methoden von KI vorgestellt
Ich stelle Dir drei Methoden vor, wie eine KI ausehen kann
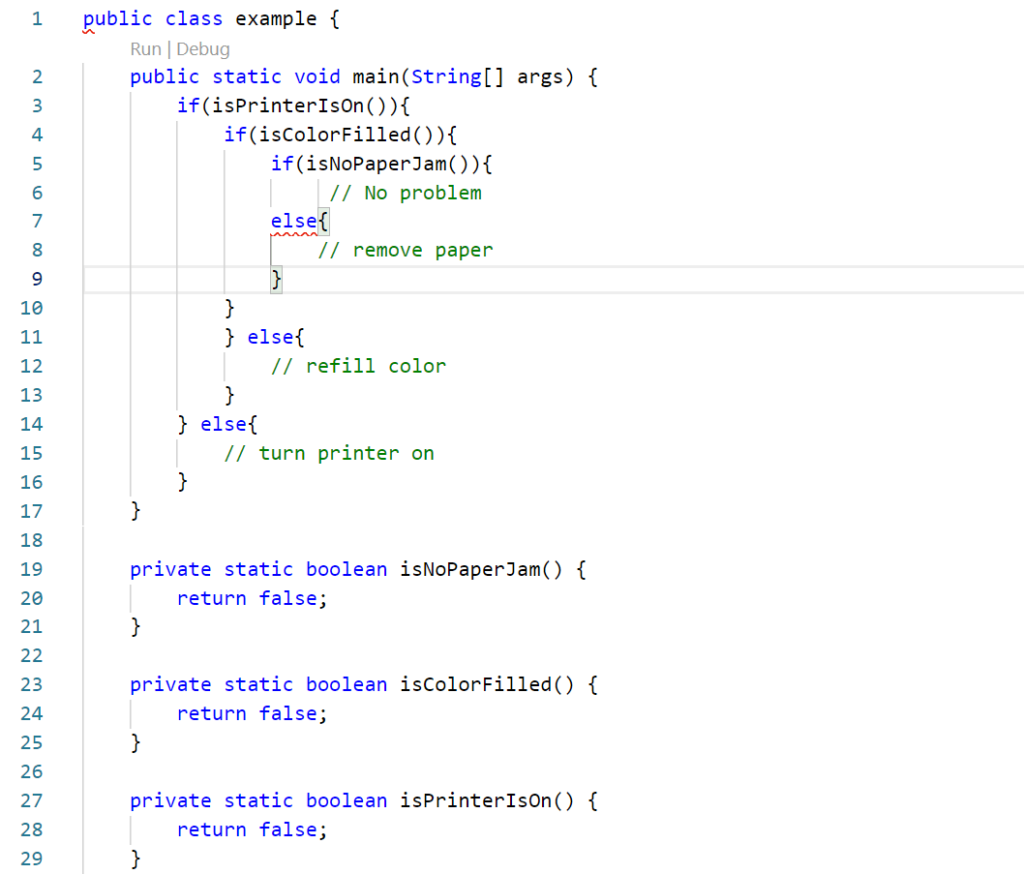
Simple Künstliche Intelligenz – Entscheidungsbaum
Ein paar verschachtelte if-Anweisungen (Wenn-dann-Verzweigung) dürfte als Künstliche Intelligenz gelten. Dieses einfaches Konstrukt ist die Voraussetzung für ein Expertensystem:
Ist der Drucker eingeschaltet? Wenn(ja) -> X Sonst -> Y
Sind die Patronen voll?
Ist ein Papierstau im Einzug?
Künstliche Intelligenz auf Basis von Web-Mining
Eine KI auf Web-Mining Basis kann aus der Wortwahl der twitternden Menge an Demonstranten vorhersagen, ob Ausschreitungen zu erwarten sind.
Die Stochastik vereinfacht:
Friedliche Demo 0 % – 50 % Ausschreitungen – 100 % Bürgerkrieg
Falls 100 der 1000 Demonstranten Worte tweeten wie „Schlag“, „Ausrasten“, „Polieren“ oder „Werfen“, dann erhört sich die Wahrscheinlichkeit.
Falls der Großteil mehr sachliche Kommentare auf Twitter veröffentlichen senkt die KI die Wahrscheinlichkeit.
Welche Worte sind für eine solche Analyse relevant oder irrelevant? Ein Machine Learning Programm ermittelt diese. Die KI betrachtet den folgenden Datensatz an
- Texte aller Tweet unter dem Hashtag Demo X (30.000 Wörter)
- Ausschreitung (wahr, falsch)
- Anzahl das Verletzen
Die Beschriftung durch das Feld 2 und 3 helfen der KI, die relevanten Worte zu finden. Was ist die Schnittmenge der Worte aus 60 Demos, wo es zu einer Ausschreitung gekommen ist? Der Algorithmus wird nicht die Worte ausspucken, die Demo-spezifisch (Grund der Demo) oder generische Wörter sind (Stopwords).
Stopwords sind Füllwörter ohne viele inhaltliche Bedeutung (ist, man, du, eine, der, deine, sein, haben).
Link Tipp: Common Crawl für ungefilterte Webdaten für Deine Analysen
Künstliche Intelligenz via Regression
Die Regression ist ein statistisches Modell, welches versucht den Zusammenhang von Ursache(n) und einem Resultat herzustellen. Die Anwendungen der Regression sind vielfältig:
- Bruttonationaleinkommen eines Landes auf Basis der Anzahl der Erwerbstätigen vorhersagen
- Gehalt eines Absolventen anhand der Abgangsnote vorhersagen
- Anzahl der Punkte in einer Klausur anhand der gelernten Stunden vorhersagen
- Körpergewicht anhand der täglich konsumierten Kalorien vorhersagen.
Ursachen sind die „unabhängigen“ Variablen, die das Resultat, die abhängige Variable, beeinflusst.
Typen von Variablen sind …
- Nominale: Geschlecht [Weiblich, Divers, Männlich], Süchte [Raucher / Nicht-Raucher]
- Ordinale Schulnoten [1,2,3,4,5,6]
- Metrische: Alter, Gewicht, Größe (Kontinuierliches Maße)
Die Regression eignet sich für die Vorhersage, wie alt Du wirst, wenn Du Deinen Lebensstil nicht änderst. Eine häufige Denkfalle ist, dass Korrelation nicht gleich die Kausalität. Wer im Sommer joggt, bekommt häufiger Sonnenbrand als jemand, der eine Couch-Potato ist. Das stimmt aber nicht. Würde die Couch-Potato in der Sonne liegen dann, hat sie genau so Sonnenbrand. Das Joggen ist nicht kausal zusammenhängend mit dem Sonnenbrand.
Beispiel einer Regression
Zwei unabhängige (willkürlich ausgewählte) Faktoren können Deine Lebenszeit bestimmen:
- Schlaf: Wie viel Stunden / Minuten am Tag schläfst Du? 8 Stunden Schlaf sind optimal und je mehr oder weniger Du schläfst, desto früher stirbst Du.
- Sport: Wie lange am Tag bewegst Du Dich? Je mehr Sport Du treibst, desto länger lebst Du. Wenn Du es übertreibst, kippst Du früher um.
Für repräsentative Daten brauchst Du ca. 1000 Personen. Diese musst Du über ihr Leben beobachten und den Sterbezeitpunkt notieren. Diese Daten Sammeln Forscher über mehrere Generationen, sodass ein großer Datensatz entsteht.
Erste Schritte
Als Erstes solltest Du Dir eine Übersicht über die Daten verschaffen. Lasse dazu zwei Punktewolken-Diagramme für Schlaf-Alter und Sport-Alter ausgeben.
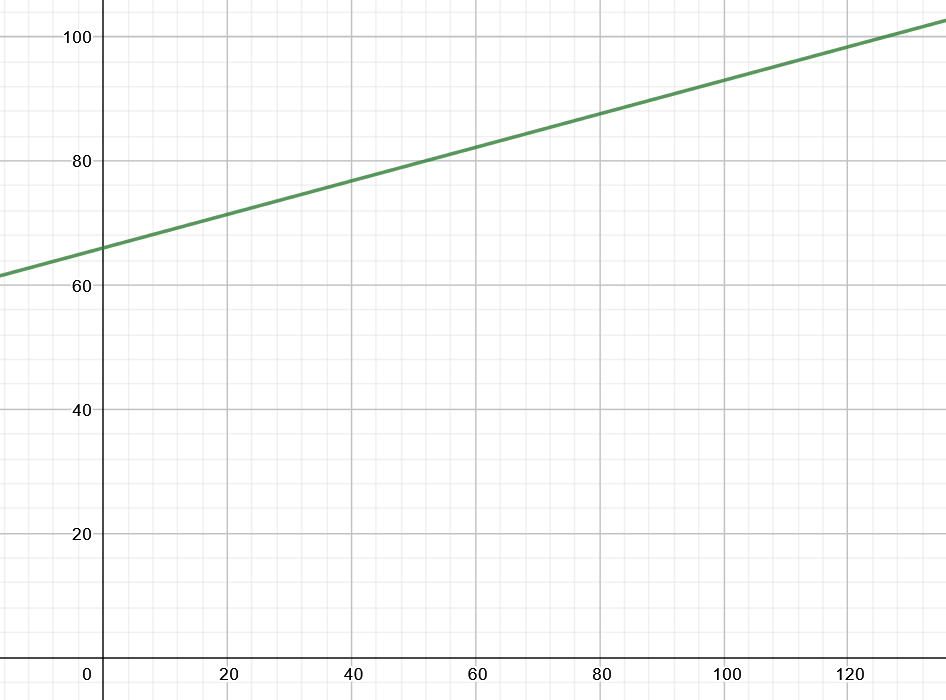
Jetzt kannst Du entscheiden, ob der Zusammenhang zwischen den Variablen linear oder nicht linear ist. Bei einem linearen Zusammenhang könntest Du durch die Punktewolke eine Gerade ziehen und über eine lineare Gleichung das Alter zu der täglichen Gewohnheit bestimmen.
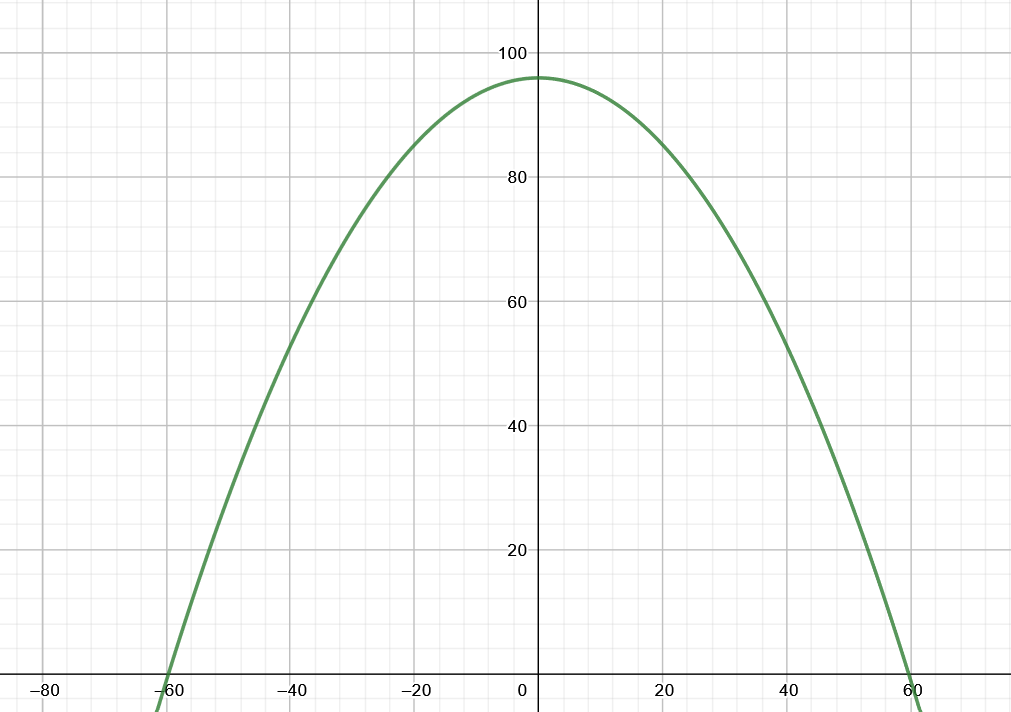
Auswertung und Erstellung des Modells
Wenn Du Dir Objekte gut räumlich vorstellen kannst, kannst Du Dir einen 3-D-Grafen mit Z = Alter, X = Sport und Y = Schlaf ausgeben. Der Plot sollte Dir eine Haube zeigen, die einen Hochpunkt (höchstes Alter) bei optimalen Schlaf- und Sport-Gewohnheiten zeigt.
Das Modell der Künstlichen Intelligenz sieht so aus, wenn ein linearer Zusammenhang besteht
60 + 2 (Stunden Schlaf) + 0.5 (Minuten Sport) = vorhergesagtes Alter
Bei 7 Stunden Schlaf und 30 Minuten Sport pro Tag sind, dass ein Alter von 89 Jahren.



bin durch chat.bing.com auf deinen Blog gestoßen, weil ich verstehen will wie KI funktioniert und finde deine Beiträge sehr gut erklärt. Danke.
Danke
schön und klar erklärt – danke.
… nur weil man mit „Algorithmus“ nichts anfangen kann heisst es nun KI und mit „Intelligenz“ wissen wir ja alle was gemeint ist 🙂
ich bleie dabei – einen Witz ER-/oder FINDEN macht den Unterschied 🙂
Danke. Interessante Idee