
Du möchtest das Clustering besser verstehen?
Dieser Guide erklärt Dir die Algorithmen DBSCAN und BIRCH!
Starten wir!
Die Welt der Clustering
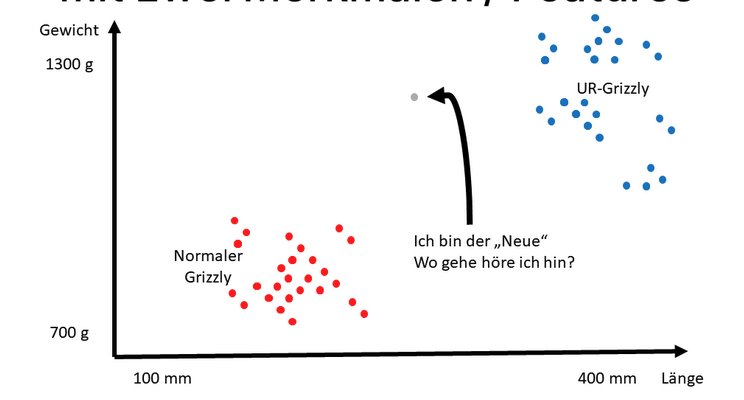
Was bedeutet Clustern eigentlich?
Unser menschliches Auge kann sehr gut visuelle Objekte zu einer Gruppe zusammenfassen. Das gelingt intuitiv und ohne große Berechnungen.
Beispiel: Auf einer Messe kannst Du schnell Menschen zu einer Interessensgruppe zu ordnen, weil die Menschen dicht zusammen an einem Marktstand stehen. Der Computer kann ohne Algorithmen keine Strukturen erkennen, weil dieser nicht die gleiche Strukturen-suchende Wahrnehmung hat wie ein Mensch.
Steffen Lippke
Cluster-Methoden im Computer basieren auf Mathematik. Du kannst zwischen vielen verschiedenen Varianten wählen. Diese basieren auf der …
- Dichte
- Varianz
- Häufigkeit
- Heuristiken
- Hierarchien
- Graphen
- Neuronalen Netzen
Warum brauche ich andere Algorithmen?
Dieser Beitrag beschreibt zwei (super coole) Methoden, die für moderne Anwendungsfälle und Terabytes an Daten geeignet sind.
Die heutige Datenflut (E-Mails, Sensordaten, Chat-Nachrichten, Bilder, News, …) erschlagen die Rechenleistung und das Arbeitsspeichervolumen von den meisten Computern.
Der K-Means Algorithmus gilt als der inoffizielle Clustering-Standard, welchen Du im Informatikstudium als Erstes kennenlernst. Für die Vorlesung eignet sich K-Means super, bietet ein sehr gutes Ergebnis mit 100 Datenpunkten, aber …
Was ist das Problem mit K-Means?
Die Rechenzeit von K-Means nimmt nicht linear zu.
Wenn Du 100 Datenpunkte in 2 Cluster clusterst, schafft das Dein Computer in 2^(1*100+1) Operationen.
Bei 1.000 Datenpunkten, sind es nicht 100 Sekunden, 2^(1*1.000+1)
Schluck 🙁
Was ist eine NP-Schwere?
Nicht alle Algorithmen skalieren linear. Was bedeutet Linearität?
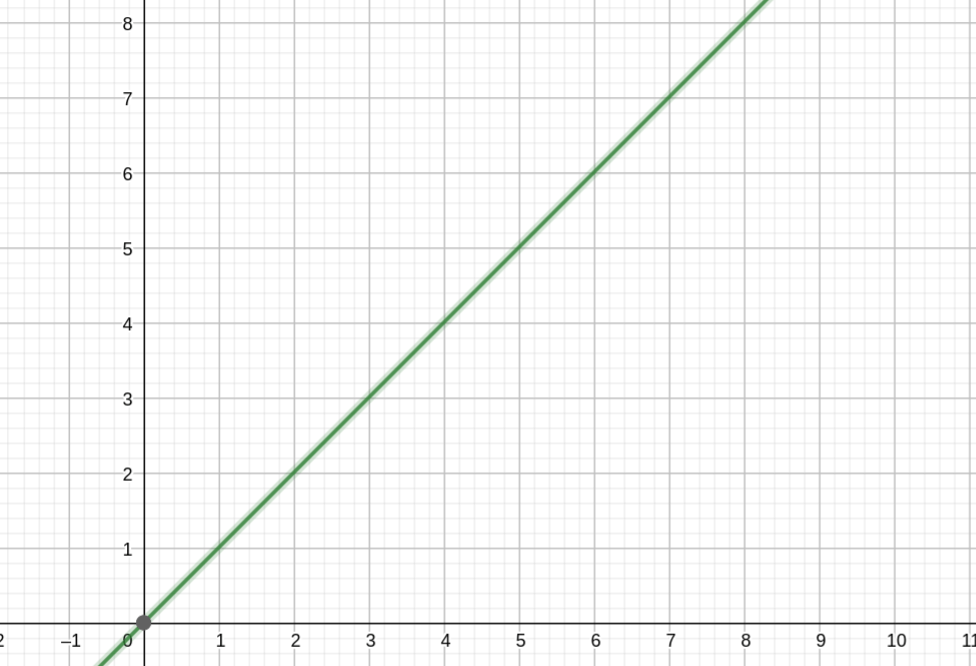
Wenn der Computer eine Aufgabe mit 100 Zahlen erhält, braucht der Computer in diesem Fall 1 Sekunde. Wenn die Aufgabe linear im Aufwand skaliert, dann braucht der Computer bei 1.000 Zahlen 10 Sekunden.
Bei nicht-polynomialen Algorithmen steigt der Aufwand bei einer Aufgaben-Verdopplung, um ein 100-faches an – bei einer Aufgaben-Verdreifachung, um 1.000.000-faches usw.
Steffen Lippke
Doppel-Schluck 🙁
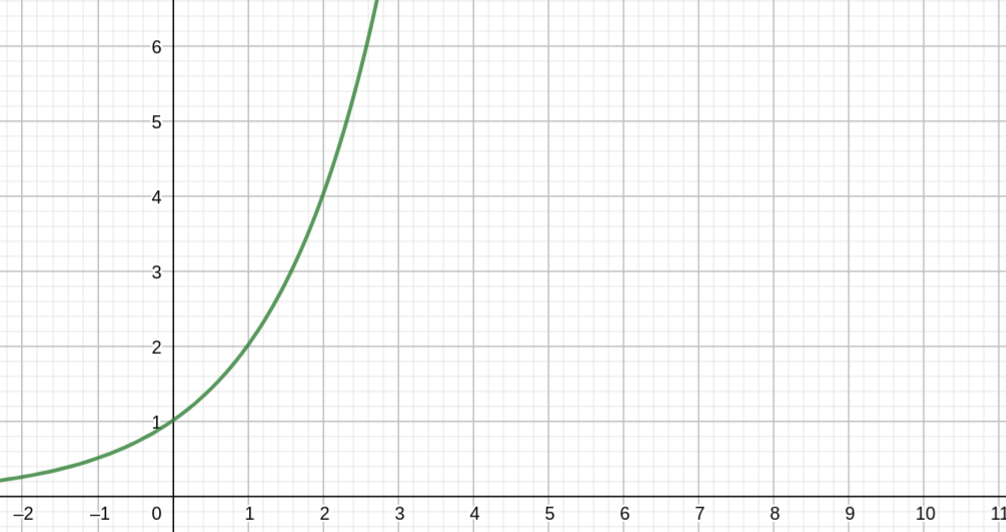
Die Informatik kennt neben K-Means weitere solche Probleme wie das Rucksack-Problem, Reisender-Kaufmann-Problem, …
Die Theoretiker in der Informatik haben die „harten Nüsse“ der Informatik auf das Erfüllbarkeitsproblem heruntergebrochen. Die große Frage lautet: „Existieren Methoden, welche die Probleme zeiteffizient lösen können“
z. B. (x²) oder (x⁵).
Weil die Informatik bisher noch keine akzeptable Lösung für dieses Problem finden konnte, gibt es viele Hilfstechniken, Modelle und „Hacks“ (Heuristiken), die das einfacher machen.
BIRCH und DBSCAN sind solche.
Erklärungen
DBSCAN einfach erklärt
DBSCAN basiert auf Dichten. Wenn Punkte dicht zusammenliegen, fasst der Algorithmus diese zu einem Cluster zusammen. DBSCAN unterscheidet …
- Kernpunkte: Befindet sich der Punkt X innerhalb einer Punktewolke und hat dieser mindestens R Nachbarn, dann nennt DBSCAN diesen Punkt einen ‚Kernpunkt‘.
- Randpunkte: Wenn weniger als R Nachbarn in der Umgebung liegen, dann nennt der Algorithmus diesen ‚Randpunkt‘. Die Kernpunkte befinden sich in unmittelbarer Nähe.
- Rauschpunkte: Nicht jeder Datensatz zeigt eindeutige Cluster auf. Ist ein starkes Grundrauschen und Streuung vorhanden, dann klassifiziert DBSCAN dies als Rauschpunkte. Ein Rauschpunkt hat keine Nachbarn in seinem direkten Umkreis.
Lese hier das ganze wissenschaftliche Paper.
BIRCH einfach erklärt
Der BIRCH-Algorithmus nutzt ein anderes Konzept, um Datenpunkte zu clustern.
Der Algorithmus basiert auf einer Hierarchie, einer Baumstruktur. Statt jeden Datenpunkt einzeln zu bewerten, fasst BIRCH im ersten Schritt mehrere Datenpunkte zusammen.
Ein Datenvektor beschreibt das Clustering-Bündel:
- Die Anzahl der Datenpunkte N
- Die lineare Summe (Vektoren!) LS
- Die Quadratsumme der Datenpunkte (Vektoren!) SS
Einem Blatt der Hierarchie beinhaltet meistens B Einträge. Der Algorithmus weist jedem Datenpunkt einen Zeiger zu einem weiteren Blatt zu. Die Blattknoten sind mit Zeigern verbunden, die eine Kette von Blättern bilden.
Das ganze Paper gibt es hier.
Anwendungsfälle
Wann soll ich BIRCH nutzen?
Der Algorithmus BIRCH ist immer sinnvoll, wenn Du nicht den kompletten Datensatz in den Arbeitsspeicher zum Cluster laden kannst. BIRCH fasst Datenpunkte zusammen und bildet eine Hierarchie aus.
Du brauchst nicht den gesamten Datensatz, um mit dem BIRCH Clustering zu starten. Wegen der Hierarchie kannst Du neue Datenpunkte mit geringem Aufwand hinzufügen.
Steffen Lippke
Bei K-Means brauchst Du in diesem Fall eine komplette Neuberechnung. Die Vorgänger von BIRCH treffen für jeden neuen Datenpunkt eine eigene neue Cluster-Entscheidung. Die Heuristik BIRCH verallgemeinert die Entscheidungen, um die Rechenzeit zu verkürzen und den Arbeitsspeicher zu limitieren.
Typische Anwendungsfälle:
- Wenig Arbeitsspeicher
- metrische Daten
- Kundendaten → Aufteilung in Segmente
- Pflanzenarten bestimmen → Messwerte klassifizieren
Wann soll ich DBSCAN nutzen?
Der Algorithmus DBSCAN eignet sich für die Ausreißer-Analyse. Der Algorithmus bildet Cluster anhand der Dichte. Die Clusteranzahl hängt von der Beschaffenheit der Daten ab. Bei den Algorithmen K-Means und BIRCH musst Du von Anfang an eine Clusteranzahl vorgeben. Ist der Datensatz stark verrauscht, ist K-Means nicht die beste Wahl.
Falls Du einen neuen Datenpunkt zu den geclusterten Datenpunkte hinzufügen willst, dann fügt DBSCAN den neuen einfach hinzu. Die Datenpunkte in der Umgebung können z. B. von Randdatenpunkten zu Kerndatenpunkte aufsteigen, weil dann R als Anzahl erfüllt ist. Die übrigen geclusterten Daten bleiben unberührt.
Typische Anwendungsfälle:
- verrauschte Daten → Bestehende Cluster nicht mit Rauschdaten überfüllen
- kein Plan wie viele Cluster sinnvoll sind
Die Clusteranzahl bei K-Means kannst Du mit der grafischen Visualisierung ‚Dendrogramms‘ bestimmen. Das Diagramm nimmt Dir nicht die Entscheidung ab, aber vereinfacht die Auswahl.
Alternativen und andere Methoden
Clustering Algorithmen findest Du in vielen Variationen. Je nach Anwendungsfall solltest Du den Algorithmus auswählen:
- Wie viele Daten muss ich clustern?
- Wie sieht die Beschaffenheit aus (verrauscht, klar)?
- Was ist mein Ziel / was ist nicht mein Ziel?
- Möchte / muss ich die Clusteranzahl vorgeben?
- Kann ich den Algorithmus in Feinheiten anpassen?
- Wie lange kann / darf ich rechnen (Kosten, Aufwand, Strom, CPU)? Wie genau muss das Clustering sein?
Beantworte diese Fragen, bevor Du Dich auf die Suche nach einem anderen Algorithmus machst.
Neuronale Netze (Feedforward Netz) clustern für Dich Inhalte. Für den Prozess brauchst Du gelabelte Daten. Die Netze musst Du im ersten Schritt mit Probedaten und den gewünschten Ergebnissen füttern. Nach dem Training sind diese einsatzbereit. Je nach Güte des Trainings klassifiziert das Netz automatisch neue Datenpunkte.
Eine Support Vector Machine clustert z. B. in 2 Gruppen. Diese eignet sich auf X-Dimensionen.


