
Du brauchst ein praxisnahes MongoDB Tutorial?
Dieser Guide erklärt Dir, alles was zu dieser neuartigen Datenbank Wissen musst.
Starten wir!
Was ist MongoDB?
MongoDB ist eine dokumentenorientierte NoSQL-Datenbank. NoSQL bedeutet Not only Structure Query Language und beschreibt einen Typ von Datenbank, der die klassischen tabellarischen Datenbanken erweitert (Relationen). NoSQL-Datenbanken sind schemafrei, horizontal skalierbar, quelloffen und mit einer Simple-API ausgestattet.
Die Eigenschaft „dokumentenorientiert“ bedeutet, dass die Datenbank zur Speicherung Dateien verwendet und keinen zeilenbasierten Wertetupel (bzw. einfach ausgerückt: Tabellen). MongoDB nutzt als Dateiformat BSON (Binary JavaScript Object Notation). Dieses Format sieht aus wie JSON und kann binäre Daten speichern.
Funktion – Grundlagen einfach erklärt
Im Gegensatz zu SQL-Datenbanken ist diese Datenbank gut horizontal skalierbar.
Horizontal skalieren
Statt einen großen, starken Computer zu bauen, kann die Software sich auf kleine, billige Computer (Nodes) verteilen. Einzelne Nodes können im laufenden Betrieb ausfallen und trotzdem erhalten alle Clients die angefragten Daten. Das System repliziert dafür die Inhalte, damit beim Fall der Fälle immer ein Backup vorhanden ist.
Der Master erhält die Schreibaufträge und repliziert dies auf die Knoten. Selbst wenn keine Anfragen an den Server gestellt werden, können Operationen auf der MongoDB Instanz stattfinden. Diese Datenbank nutzt das BASE-Schema:
Nicht ACID – sonder BASE
- Basically available: Der Cluster ist durch die Redundanzen in den meisten Fällen verfügbar und das Gesamtsystem zeigt eine hohe Zuverlässigkeit.
- Soft-State: Selbst im Ruhezustand kann das Datenbanksystem Synchronisationen durchführen, damit der Cluster seine Daten konsistent verteilen kann.
- Eventually consitent: Im Gegensatz zu SQL ist diese Datenbank IRGENDWANN konsistent und bietet keine atomaren Transaktionen an. Nach der Zeit XY ist das System wieder in einen konsistenten Zustand.
Verteiltes System erklärt
Ein verteiltes System nutzt verschiedene Techniken, um sich zu replizieren und den Client immer den neusten Datenbestand anzubieten. Eine Computer-Architektur nennt sich Master-Slave. Der Master-Computer kontrolliert und verwaltet die Slave-Computer, die die Aktionen, Lesen und Speichern, für den Master ausführen.
Der Vorteil ist, dass wir riesige Computernetzwerke erstellen können, die mehr Daten verarbeiten können als ein einzig großer starker Computer. Ein einzelner Computer ist zwar transparenter und übersichtlicher, aber ist auch ein Single Point of Failure.
Überlast? Gelöst mit MapReduce
Die Verarbeitung von großen Datenmengen bringt ein weiteres Problem mit sich.
Früher hat der Entwickler z. B. die Datenbank nach den Umsätzen abgefragt und die Daten in seinem Hauptspeicher geladen. Der Entwickler-Computer hat die Positionen aufsummiert.
Wenn die Datenbank TB an Daten zurücksendet, funktioniert das Schema nicht mehr. Statt die Daten zum Code (Entwickler) zu bringen, bringt „Map-Reduce“ der Entwickler seinen Code zu den Daten-Knoten.
Steffen Lippke
Die Daten-Knoten sind Computer, die genauso Operationen ausführen können. Nur das Endergebnis bekommt der Entwickler mitgeteilt und muss nicht seinen RAM dafür Opfern.
MongoDB Tutorial
Die Datenbank ist kostenlos und Open Source verfügbar.
Unter Windows und Linux kannst Du diese Datenbank mit dem folgenden Link downloaden:
- Downloade Dir den MSI Installer.
- Wähle aus, dass die Datenbank nicht als Service installieren möchtest.
Die Oberfläche Compass
Downloade Dir Mongo Compass für Deinen Einstieg. Diese Oberfläche ist optional und basiert auf dem Command Line Interface (CLI), die Du mit der MSI mitbekommst.
Das Tool bietet Dir eine interaktivere / visuelle Oberfläche, mit der Du Deine lokale Datenbank erreichen kannst. Grundsätzlich gilt, dass eine CLI mächtiger ist als eine GUI, weil Du Fehlermeldungen lesen kannst, Eingaben steuern und vollständige Ausgaben erhältst.
- Öffne eine CMD mit Admin Rechten
- Erstelle einen Ordner für die die Monogo-Datenbanken
mkdir C:\data\db - Gebe ein:
„C:\Program Files\MongoDB\Server\4.4\bin\mongod.exe“ –dbpath=“c:\data\db“
- Starte die Mongo-CLI
„C:\Program Files\MongoDB\Server\4.4\bin\mongo.exe“
Unter Linux mit Flatpak gehts schneller:
flatpak install flathub com.mongodb.CompassDie Datenbank nutzt Collections, die das Gleiche sind wie eine Tabelle in SQL. Du bist aber nicht gezwungen, dass alle Dokumente der Collection das gleiche Schema haben müssen.
Trotzdem solltest Du Dir genau überlegen, wie eine Datenstruktur aussehen kann. Du kannst mit der BSON Struktur Verschachtelungen bauen, welche mit SQL kaum möglich sind.
Deine Software (Frontend/ Backend) kann in der Regel nur eine Struktur gleichzeitig verarbeiten. Das heißt, dass Du Daten migrieren musst. Eine Migration ist das automatische Umschreiben der alten Datenbankeinträge in das neue Format. Das ist teuer und fehleranfällig. Lieber 20 Tage ein gutes Schema entwickeln, als 20 Tage Migrationen zu ertragen.
In Mongo schreibst Du JSON-Struktur-artige Abfragen, die Du je nach Anwendungsfall anpassen kannst.
Wenn Du die Datenbank mit Docker Compose nutzen willst, kopiere den folgenden Code
version: '3.9'
services:
mongo-crawly:
image: mongo
ports:
- '27017:27017'
container_name: mongo-crawly
restart: always
logging:
options:
max-size: 1g
environment:
- MONGO_INITDB_ROOT_USERNAME=steffen
- MONGO_INITDB_ROOT_PASSWORD=dupersicher
Der Import
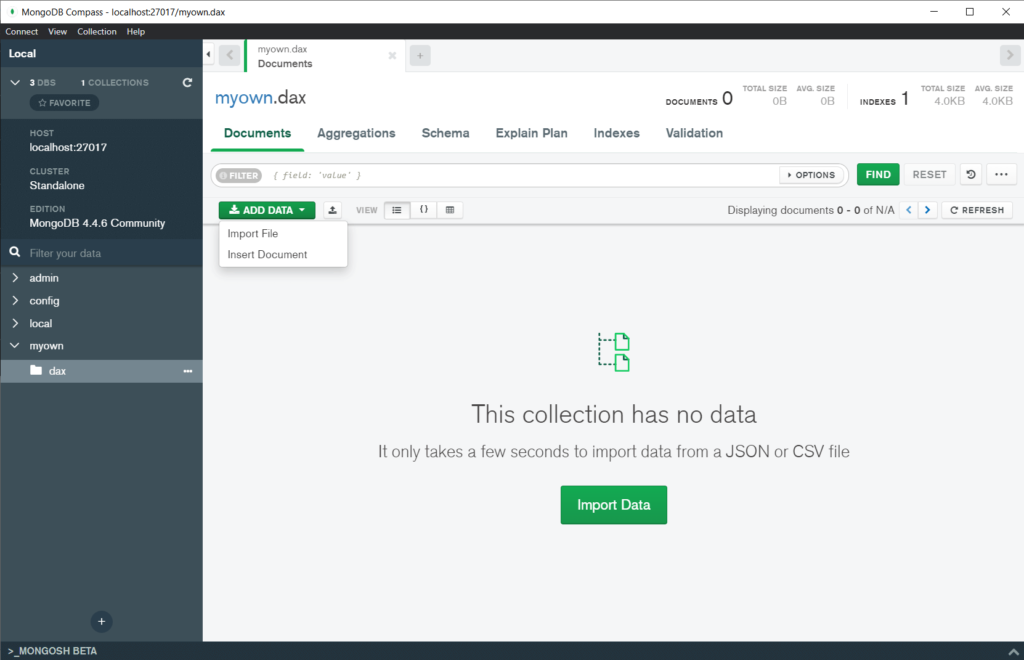
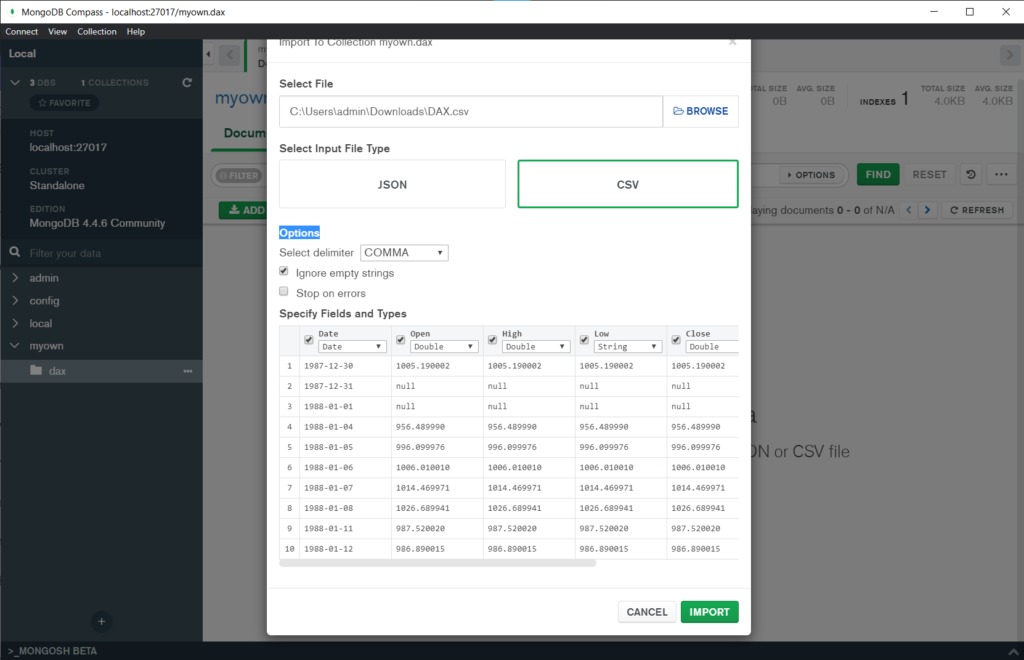
Über den CSV-zu-Dokumenten Import wollen wir die erste Tabelle importieren. Hierfür nehmen wir die Chart-Daten eines Börsen-Indexes als Grundlage (Dax). Diesen wollen mit der Abfragesprache untersuchen.
Chart Daten von allen möglichen Börsen-Indizes und Börsentiteln findest Du unter den folgenden Link. Achte beim Export darauf, dass Du die maximalen verfügbaren Tage exportierst (z.B. 1980 bis 20XX)
Klicke auf den Button Add Data und wähle Deine CSV aus und gebe zusätzlich an, welche Typen sich in der CSV befinden (Datum→ Date, Low, High usw. → Double).
So gehen die Abfragen
Um die Datenbank abzufragen, klickst Du oben in das Eingabefeld und tippst eine BSON-artige Struktur ein, um das BSON abzufragen. Das Find Kommando baut sich wie folgt auf:
- Selektion: Tippe den Namen des Felds ein (Anführungszeichen sind nicht zwingend).
- Separator: Verwende Doppelpunkt.
- Wert / Filter / Operation: Schreibe den Wert dahinter (Anführungszeichen sind nicht zwingend).
Sende die Anfrage mit dem grünen Button ab.
Der Höchststand des Tages selektieren nur die unter 5000 sind: an 3757 Tagen
{High: {$lt: 5000}}
Nur an 69 Tagen über 15000
{High: {$gt: 15000}}
… sortiere die Daten nach dem Volume um (Button Options in Zeile Sort):
{High: {$gt: 15000}}{Volume: -1}
Und zeige mir nur den Open Wert an (Project Zeile):
{High: {$gt: 15000}}{Open:1}{Volume: -1}
Suche nach einem Datum:
{"Date": new Date("1987-12-30T00:00:00.000+00:00")}
Unterhalb der Suchleiste kannst Du die Ansicht zwischen Tabellen, JSON und der klassischen Dokumentenansicht wechseln.
Wann setzte ich die Datenbank am besten ein?
Der wesentlichste Vorteil (und die Herausforderung) von MongoDB ist die Schemafreiheit.
Steffen Lippke
Du kannst die Struktur Deiner Dokumente frei wählen. Auf der anderen Seite musst Du mit jeder Schema-Änderung Deine Daten migrieren.
Die Datenbank bietet die Möglichkeit Einbettungen von „Tabellen in Tabelle“ vornehmen (JSON). Diese vorgehen kann eine sehr effiziente Abfragezeit ermöglichen. Dieses Vorgehen ist ein Graus für jeden SQL-Liebhaber und nennt sich Non First Normal Form (NFNF).
… oder über das Referenzieren über IDs, wie Du es von Fremd und Primärschlüssel aus der SQL Welt kennst.
Obwohl die Schemafreiheit gegeben ist, sollte eine langfristige Planung und ein gut-überlegtes Schema die Anzahl von Migrationen in der Produktion vermeiden.
Die Datenbank unterstützt nativ die Nutzung von geographischen Koordinaten.
Welche Anwendungsfälle sind ungeeignet?
NoSQL ist hipp.
SQL ist Old-School.
Das stimmt nicht! SQL ist immer noch die erste Wahl für Anwendungsfälle, die 100 % konsistent sein sollten. SQL verwenden Banken, um die Transaktionen vollständig durchzuführen. Wenn z. B. Du Dich bei der IBAN vertippst, sollte der Prozess das Geld nicht vernichten (Deflation), sondern eine Rückabwicklung durchführen (Rollback).
Ein Old-School SQL-Denken ist nicht bei jeder Anwendung.
Steffen Lippke
Enterprise Ressource Planning Systeme verwenden SQL Tabellen, um die Konsistenz zu wahren. Wenn der Lagerist aus dem Lager eine Entnahme bucht, dann muss das System alle Tabelle zugleich aktualisieren (Transaktion). Falls die Buchung schiefläuft, muss der Lagerist vor der Entnahme den IT-Support informieren.
Mit Python Daten aus der MongoDB erhalten
Datenbanken sind toll – noch toller sind die Daten, wenn Du diese auch verwendest. Die Datenbankentwickler stellen für viele Programmiersprachen SDKs zur Verfügung, mit welchen Du auf die Datenbank zugreifen kannst. Hier ist ein Beispiel mit Python.
- Erstelle eine
.envDatei, um die Credentials zu speichern. Wir wollen Code und Zugangsdaten separieren.
secretUser = "steffen"
secretKey = "makmaka2342"- Erstelle ein
.gitignore. Es bringt nichts, wenn GIT die Zugangsdaten in ein Repo sendet.
.env- Erstelle die Python-Datei. Lade zuerst die .env Datei mit
load_dotenv(). Die Mongo Instanz adressierst Du mitmongodb://IP-Adresse:PORT/. Wähle die Datenbank aus „crawly“ und dann die Tabelle (Collection) „pipeline„. Führe eine Suche mitfind_oneaus, um genau ein Objekt zu erhalten.
import pymongo
from dotenv import load_dotenv
import os
load_dotenv()
myclient = pymongo.MongoClient("mongodb://192.188.168.79:27017/", username=os.environ.get('secretUser'), password=os.environ.get('secretKey'))
mydb = myclient["crawly"]
mycol = mydb["pipeline"]
isInDB = mycol.find_one({"link":link})


