
Was ist TTS?
Warum soll ich TTS nutzen und können Computer sprechen?
Dieser Guide gibt Dir eine Erklärung!
Was ist Text-To-Speach – Text vorlesen lassen?
Eine Text-zu-Sprache-Software (Text2Speach) ist ein Programm, welches digitalisierte Worte einer menschlichen Sprache in eine Audiotonspur umwandelt. Der Text liegt in einem .txt, .docx oder .pdf Format vor. Ein Algorithmus verbalisiert die Inhalte mithilfe von Aufnahmen von menschlichen Vokalen, Lauten oder Worten.
Warum Texte vorlesen lassen?
- Multitasking: Statt eine E-Mail, Buch oder PDF mit den Augen Wort für Wort zu lesen, kannst Du stattdessen diese konvertieren und Dir den Text vorlesen lassen. Währenddessen kannst Du an anderen Sachen arbeiten, ohne Deine zwei Augen auf den Text zu fixieren.
- Keine freien Hände: Beim Autofahren, Kochen oder Putzen möchtest Du nebenbei etwas lernen? Das Lernmaterial liegt in Textform als Tutorial, Blogeintrag vor? Statt auf ein Display zu starren, liest Dir Dein Gerät den Text vor und Du kannst Deine freien Hände anders nutzen.
- Handycap: Manchmal strengt Dich das Lesen wegen medizinischen Gründen zu sehr an, sodass Du die Sprachversion bevorzugst.
- Aufbereitung von Inhalten: Statt nur einen Text im Internet anzubieten, kannst Du zusätzlich eine Art Podcast-Version des Texts anbieten, welchen die Besucher sich anhören können.
Was ist Natural Language Processing (NLP)?
Natural Lanuage Processing ist ein Teilgebiet der Informatik, welches sich mit der Eingabe, Verarbeitung und Ausgaben von menschlicher Sprache in Text und auditiver Form beschäftigt.
Über sieben Stufen versucht ein NLP-System ein akustisches Signal inhaltlich zu verstehen.
Fortgeschrittene NLP-System reagieren auf den Inhalt, führen Interaktionen aus und antworten Dir in vollständigen Sätzen.
Technische Ansätze und Funktionen
Die TTS Stimmen sind mit zwei Varianten verfügbar:
Konkatenieren – Verbindungen schaffen
Eine Form von TTS nutzt Aufnahmen von menschlichen Sätzen, Worten oder Lauten und verbindet diese zu einem vollständigen Text. Je feinteiliger die Audiosequenzen sind, desto mehr Worte kann das System bilden.
- Textverständnis: Der Computer leitet aus nicht sprechbaren Wörtern, Symbolen, Abkürzungen und Zahlen einen ausformulierten Text ab. Aus 1 wird eine „ein“ und aus „bzw.“ wird beziehungsweise.
- Übersetzung: Ein weiterer Algorithmus wandelt den ausformulierten Text in Lautsymbole um, die sprechbar sind. Wenn Deutsche Englisch lernen, dann müssen sie verstehen, wie sie ein „The“ sprechen. Das Voiced dental fricative ðə / ði ist das passende Lautsymbol. Diese Lautsprache ist so universal, dass mehrere Sprachen gleichzeitig diese beschreiben können.
- Natürlichkeit emulieren: Wie sehen natürliche Rhythmen und Betonungen in einer menschlichen Sprache aus? Ein Beispiel: Am Ende der Frage geht die Stimme hoch (höhere Laute).
- Sprachsynthese: Der Computer generiert mit der Lautabstraktion eine Folge von Lauten, die der Hörer als eine Stimme wahr nimmt.
Mehr dazu in diesem Paper
Statistisch – Keine Datenbank
Der Computer berechnet mit dem Hidden Markov Modell (HHM) die Tonhöhe von der Stimme neu. Das Hidden Markov Modell baut auf Wahrscheinlichkeiten auf: Wie wahrscheinlich ist das nach Laut X der Laut Y kommt.
Kostenlose vs. kostenpflichtige Programme
Open-Source-Programme sind genial, bieten aber nicht immer die besten TTS-Sprachen. Große Unternehmen stecken einen riesigen Aufwand in eine NTP/TTS-Software, damit diese natürlich wirkt.
Die Programme hinter Alexa, Cortana und Siri entstehen nicht über Nacht. Die Stimmen und Aufnahmen müssen ohne jegliche Störung aufgenommen sein, sonst hört sich das Endergebnis bruchstückhaft an.
Torsten Müller (https://github.com/thorstenMueller/Thorsten-Voice) hat seine „Stimme für die Open-Source-Community“ gespendet (2400 Aufnahmen in 8 Arten).
Viele Stunden Arbeit fließen in die Nachbereitung einer solchen Stimme hinein, bis der Algorithmus sauber arbeitet. Der Sprecher muss Texte mit einer gleichbleibenden Stimme aufnehmen. Soll die synthetisierte Stimme „wütend“ klingen, brauchen wir noch mehr Aufnahmen.
Tutorial TTS installieren
TTS mit Windows (SAPI 5.4)
Microsoft stellt mehrere deutsche Windows-Stimmen zur Verfügung. Sie kann Abkürzungen verbalisieren und Zahlen flüssig sprechen. Bei unbekannten Worten und bei manchen Genitiven holpert die Stimmen etwas. Insgesamt hören sich diese TTS-Stimmen sind sehr gut an. Die TTS-Stimmen sind in der Windows Lizenz im Sprachpaket inkludiert.
- Installiere Dir das Programm Autohotkey, um einen Shortcut Deiner Wahl mit der Sprechfunktion (TTS) zu belegen.
- Erstelle ein Skript speak.ahk und füge den folgenden Code ein:
; Read
^1::
clipboard := ""
Send ^c
ClipWait, 0.5
say := "<LANG LANGID=""407"">" clipboard " </LANG>"
Voice:=ComObjCreate("SAPI.SpVoice")
Voice.Speak(say,1)
return
; Read
^2::
clipboard := ""
Send ^c
ClipWait, 0.5
say := "<LANG LANGID=""809"">" clipboard " </LANG>"
Voice:=ComObjCreate("SAPI.SpVoice")
Voice.Speak(say,1)
return- Kompiliere den Code mit einem links Klick auf die gespeicherte Version
- Klicke auf die .exe. Ein Icon soll unten in Deiner Taskbar in der Nähe des W-LAN-Symbols erscheinen.
- Markiere mit dem Cursor einen deutschen Text und drücke Strg+1 für Deutsch (Strg+2 für Englisch)
Installieren in Linux (SOX)
Viele unterschätzen die Linux SOX Text-2-Speech. Diese Software liest Dir Text vor und verbalisiert dir jeden Text. Andere Linux Stimmen müssen dringend zum Zahnarzt, wenn diese auf Deutsch eingestellt sind, oder hören sich an wie ein Roboter aus den 80ern.
sudo apt-get install -y libttspico-utils sox
sudo apt-get install -y xclip sudo apt-get install -y xsel
pico2wave --lang=de-DE --wave=/tmp/test.wav "Guten Morgen"; aplay /tmp/test.wav; rm /tmp/test.wav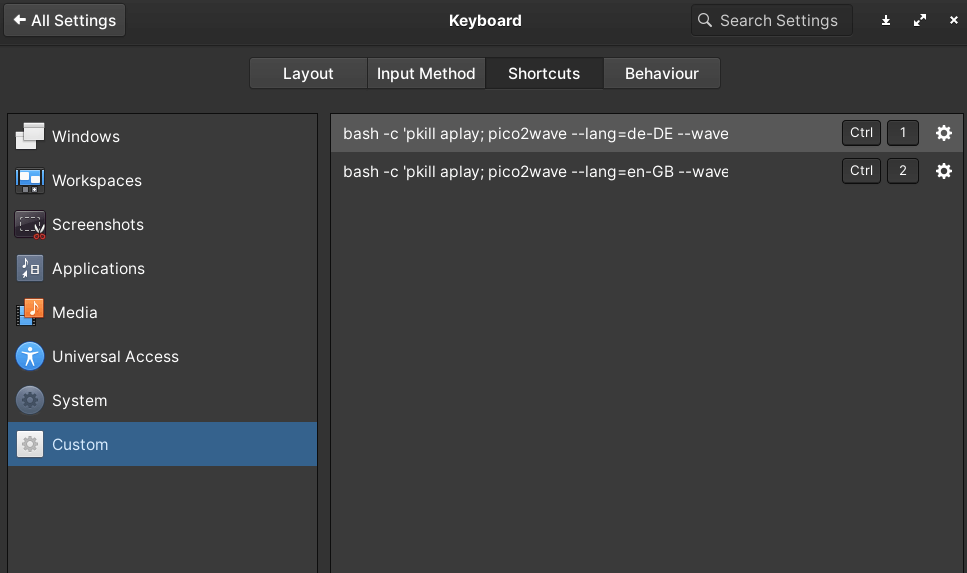
Die klassischen Ansätze für TTS können die meisten modernen Computer ohne Schwierigkeit und ohne große Latenz erledigen, sodass Du keine spezielle Hardware brauchst.
Die Ansätze, die auf neuronalen Netzen basieren, brauche im Idealfall einen Grafikkarte (GPU), um effizient und latenzlos den Text wiederzugeben. Die Systeme wie Larynx https://github.com/rhasspy/larynx bieten verschiedene Qualitäten an. Je höher die Tonqualität, desto länger muss die GPU rechnen. Die CPU kann diese Aufgabe auch erledigen, ist aber nicht so effizient.
Datenschutz und Sicherheit
Wenn Du eine Anwendungsschnittstelle für die Konvertierung nutzt, dann weiß der API-Anbieter, was für Texte du verbalisiert haben möchtest. Der API-Anbieter sollte die Texte nur im RAM temporär speichern. Die Realität ist oftmals eine andere.
Alternative zur echten Stimme?
TTS ist kein Ersatz für die echte Stimme.
Steffen Lippke
Diese können Menschen viel effektiver einsetzen, den Worten eine Tonfarbe geben (erheitert, verärgert, gelangweilt). Artikulationen und besondere Wortbetonungen schafft das TTS-Programm nicht.
Die Software ist nicht fähig, Dialekte und Wandlungen der Sprache wiederzugeben. In der Regel tätigen die Grundlagen-Aufnahmen Menschen mit einem reinen Hochdeutsch.
Bei neuen Wörtern, Randfälle oder anderen „Störungen“ klinkt sich die Software aus und gibt ein holpriges Wort von sich.


